The Right Tools For The Job
How BuzzFeed Tech is enhancing modern large language models for its content experimentation.

These days, Generative AI dominates the headlines. Whether it’s passing the bar, or just helping high school students plagiarize, it seems like ChatGPT is a frequent topic of conversation. One popular theme in these conversations is the inevitable sea change faced by businesses of all stripes.
But these conversations aren’t relegated to coffee shops and dinner tables; they’re also happening in breakout rooms and Zoom meetings. This has been doubly true at BuzzFeed over the last couple of years, especially since last Fall when we considerably accelerated our adoption of Generative AI tools. The why was clear from the start — to usher in a new era of creativity with humans at the wheel — but the how is an open problem.
Two exciting recent projects come to mind, and provide a nice case study for how we’re building with & for Generative AI at BuzzFeed.
Chatbots provide a new way for users to engage with brands, and reduce friction from highly intent-driven mechanisms like Search. Instead of identifying the appropriate search engine and translating a problem into a search query, users can consult brands like Tasty the same way they would seek counsel from a trusted [homecook] friend.
Similarly, ChatGPT Plugins also provide a novel manner of engagement, and have the added benefit of introducing a new distribution channel for content in the BuzzFeed family of brands.
We’ve had a blast solving exciting new problems these past months, and have accumulated a few lessons we’d like to share with the larger engineering community. Some of these challenges were due to OpenAI’s dataset recency limitations; the datasets used for training popular off-the-shelf LLMs cover the past — not the present — and cannot reason about current events. Others were interface challenges like the limited context window: how does one squeeze decades of articles and recipes into a 4k token context window?
Early tests
Our early projects — games like Under The Influencer, and the Infinity Quizzes — were powered by “vanilla” ChatGPT v3.5 running carefully crafted prompts. Some of the limitations were charming but harmless, like the inability to perform basic arithmetic. Other limitations were more significant, like the decline in performance for system prompts containing 5+ rules, leading us to break complex instructions into multiple API calls used to inform the control flow.
Foiled path
Buoyed by the reception of these early projects, we explored self-hosting fine-tuned LLMs like FLAN-T5. In part, this plan made sense; innovations like LoRA made fine-tuning LLMs on our data a reasonable proposition. But the economics of self-hosting — a game of thin margins that can shrink dramatically whenever OpenAI makes an announcement — sent us back to the drawing board.
Glimmer of hope
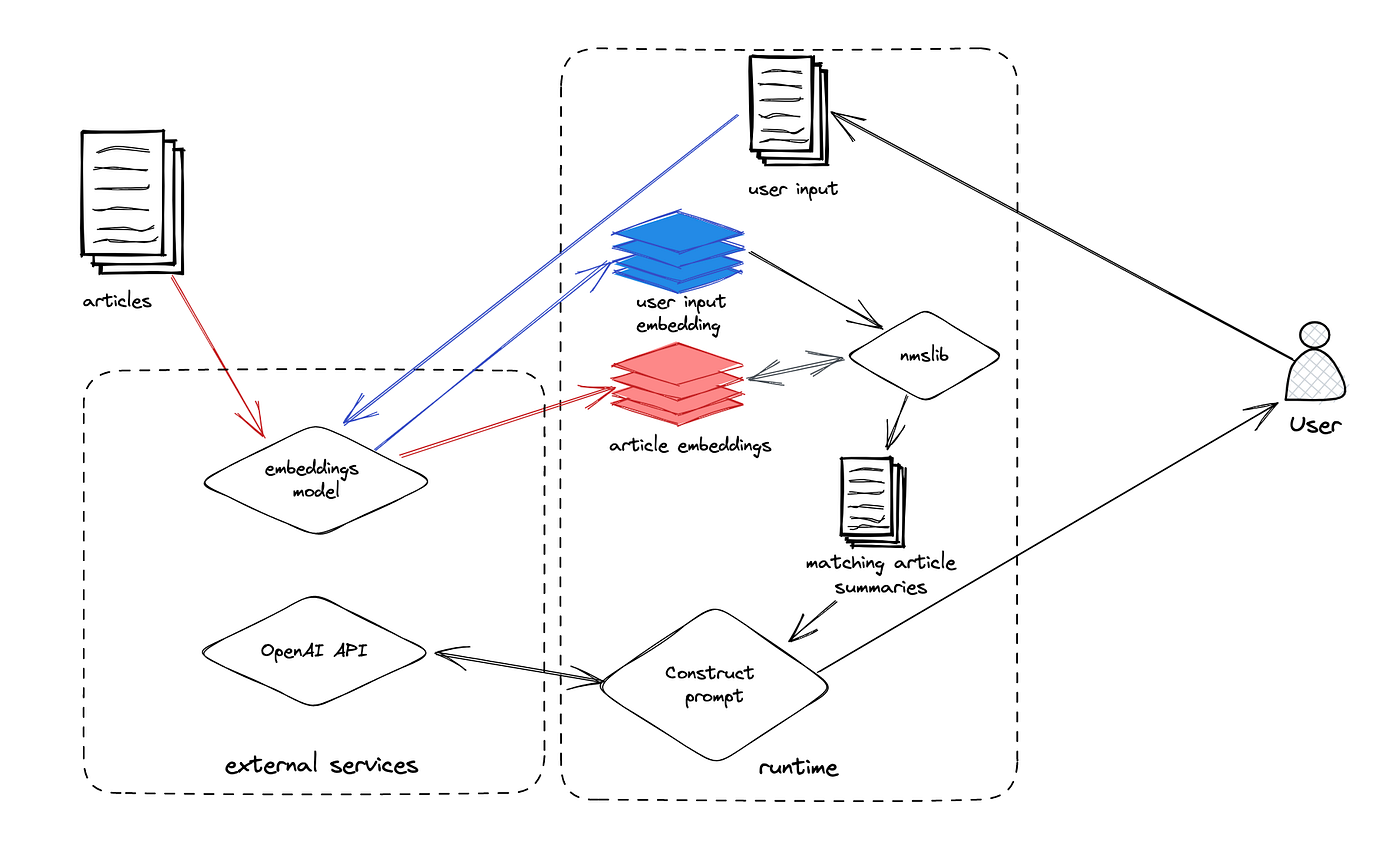
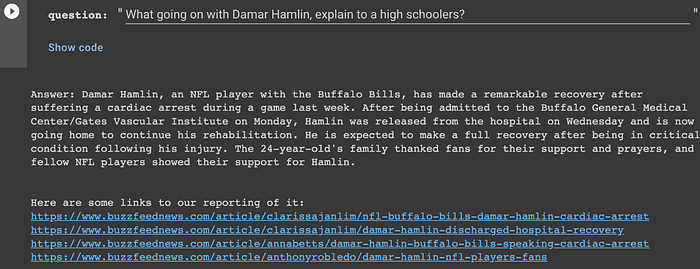
BFN Answering Machine, an internal chatbot with knowledge of recent BuzzFeed News articles, aimed to address the dataset recency limitation using a Semantic Search + LLMs technique. Semantic [or “embeddings-based”] search involves projecting a corpus into vector space, and applying the same transformation to search queries before performing a simple nearest neighbor search to elicit matches.
So after generating embeddings for a corpus of BuzzFeed News articles, we were able to perform nearest-neighbor searches on the embedded representation of the user’s query using nmslib. Including the top k matches in the prompt passed to openai.Completion.create() allowed BFN Answering Machine to authoritatively answer questions about current events.
Production readiness
Semantic search was a winner, but since nmslib in a Colab Notebook wasn’t quite production-grade, we got to work improving our Nearest Neighbor Search Architecture. This architecture has powered Personalization and Content Recommendations for years, but was a clear priority for enabling semantic search in all our Generative AI projects. The previous version, backed by Google’s Matching Engine product, leveraged internal microservices for embedding content (e.g. recipes, articles) and hydrating search results back into a standard format usable by all applications.
The new architecture, an event-driven system powered by NSQ (a core technology in the BuzzFeed stack), introduces a number of improvements in developer experience, performance, and cost-efficiency. Batch endpoints simplify experimentation (e.g. building new large indexes from a data scientist’s notebook), and improve throughput on production workloads. A decoupled interface for backend vector databases allowed us to ditch Matching Engine for Pinecone, netting us immediate savings on our monthly GCP bill.
Having addressed those concerns about the dataset recency limitation, we knew we still needed a fix for the limited context window.
Careful with Open source
Our first foray into retrieval-augmented generation saw us spending hours with LangChain, a framework that formalizes control flow logic powered by an LLM’s response to simpler subqueries, and an out-of-the-box implementation of ReAct.
ReAct synergizes reasoning and action by using “LLMs to generate both reasoning traces and task-specific actions in an interleaved manner”. LangChain’s out-of-the-box implementation is easy to get started with.
We saw the benefits of such a concise representation, but eventually outgrew LangChain’s “batteries included” philosophy. Most notably,
- We needed more control over error-handling & instrumentation with our metrics tooling (e.g. How many calls are we making to OpenAI)
- We needed more control over when calls are made to OpenAI
- LangChain crashed when the learned heuristics (e.g. which tool to use in which scenario) conflicted with provided system-prompt instructions
Roll with knowns
Hot open source projects are dominating the space , and we know perusing source code to fill in documentation gaps is sometimes a sign you’re betting on the right horse. But after struggling to make LangChain work for us, we (like many others) decided to abandon LangChain in favor of a simpler homegrown implementation we call “native ReAct” because of its faithfulness to the original paper. This allows us to handle the reasoning & candidate generation internally while still leveraging OpenAI models for the actual text generation.
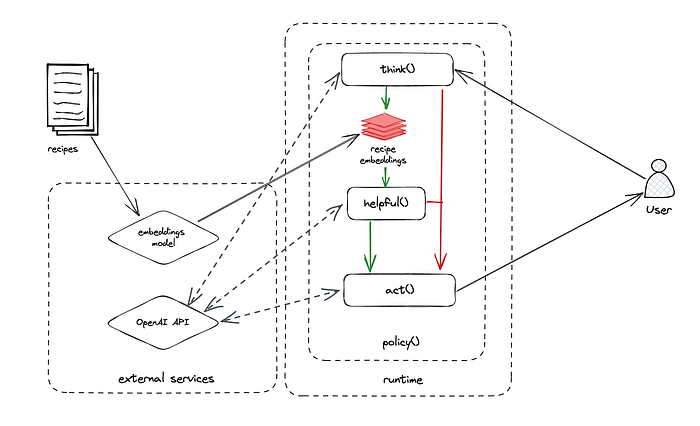
OpenAI has solved the text generation problem, but using it in our products illuminated a new class of technical challenges. By investing in our Nearest Neighbors Search Architecture, we’re able to consistently update the LLMs context with information (recipes, articles, products) newer than October 2021. And by hand-rolling an implementation of ReAct, we can better control how a given application chooses to use that supplemental context without sacrificing interoperability with our existing monitoring/metrics reporting stack.
Many thanks to Archi Mitra, Max Woolf, and Clément Huyghebaert for their contributions to this article.

